Den tradisjonelle databasen lagrer data i form av poster. Hver post inneholder et antall felter der ett eller flere felter i kombinasjon utgjør en entydig identifikasjon – postens nøkkel. Databasene vokste ut av de postorienterte filsystemene, der alle poster var lagret i en sekvensiell fil. Databasene utviklet strukturer, eller relasjoner, mellom posttypene. Først kom en ren trestruktur også kalt hierarkisk modell med IBMs IMS. Poster i trestrukturer lar seg linearisere, det vil si at de kan lagres etter hverandre på sekvensielle medier, for eksempel magnetbånd.
Med inntog av disker som er adresserbare, kunne en ved hjelp av pekere (adresser) hoppe fra én post til en annen, og det gir muligheter for mer avanserte strukturer hvor en lenker sammen poster. Datamodeller basert på lenker kalles settbaserte modeller. Postene i en lenke danner et sett, og posten som lenken starter fra blir settets eierpost. Når samme post inngår i flere lenker dannes en nettverksstruktur. CODASYL foreslo i 1971 en standard for databasesystemer, både strukturell utforming og operasjoner, basert på en nettverksstruktur av lenkede lister.
De settbaserte (lenkede lister av poster) var omstendelige å programmere. I 1970 lanserte Edgar Frank Codd relasjonsmodellen som prioriterte enkelthet og enklere programmering, samt at den var basert på en helhetlig teoretisk modell. Problemet var at ingen ennå kunne fortelle hvordan systemet kunne realiseres i praksis slik at en oppnådde akseptabel kapasitet.
1970-årene var preget av at operative databaser var realisert av databasesystemer basert på settmodellen, enten trestrukturert modell eller nettverksmodellen (CODASYL-modellen). Forskningsmiljøene prøvde å finne løsninger på hvordan relasjonsmodellen kunne realiseres for praktisk bruk. Blant annet ble det bygget flere databasemaskiner med spesialisert maskinvare.
Fra slutten av 1970-årene ble relasjonsdatabasesystemer mest vanlig, typisk i en klient-/tjenerarkitektur. Dette ga rom for at flere (klient-)programmer kunne aksessere samme databasesystem (tjener) over et datanett. Relasjonsdatabaser har overlevd teknologisk ved at både hardvare, fysisk lagringsmedium og datakommunikasjon har blitt stadig billigere og raskere. Dette inkluderer ulike distribuerte løsninger for både prosessering (ytelse) og lagring av data. I tillegg har kommersielle aktører sørget for å optimalisere og tilpasse sine databasesystemer etter hva kundene/markedet har etterspurt.
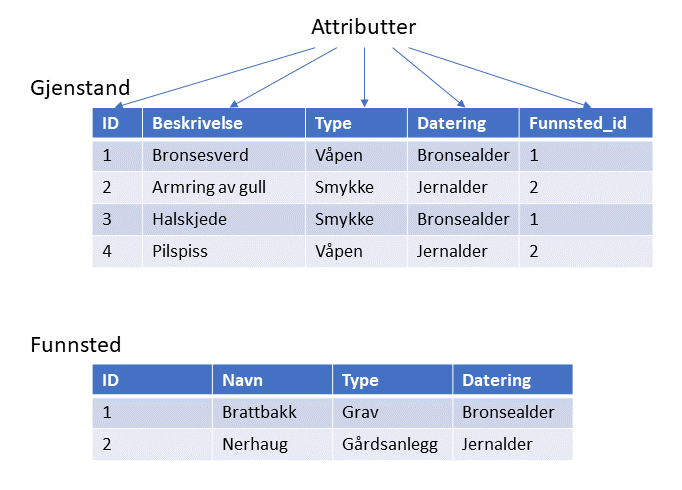
I 1976 ble ER (Entitets Relasjons)-modellen introdusert. Dette er en såkalt konseptuell datamodell for visualisering av databasen i form av en figur, kalt ER-diagram. ER-diagram er ikke teoretisk knyttet til relasjonsdatabase, men i praktisk bruk er det vanlig at et ER-diagram viser databasens struktur. Dette letter forståelsen for databasens oppbygging for utenforstående, og har derfor vært viktig for utbredelsen av spesielt relasjonsdatabase. Kommersielt finnes det verktøy som automatisk oversetter mellom ER-diagram og relasjonsdatabase. Et tidlig eksempel på et slikt verktøy er Modelator, utviklet av det norske selskapet Metodedata.
Sent på 1980-tallet og innover på 1990-tallet kom først objektorienterte datamodeller og deretter objektrelasjonsdatabaser. Objektorientert tankegang ble veldig populært innen systemutvikling eller programmering i denne perioden. Fullt ut objektorienterte databasesystemer representerer data som objekter med mulighet for å inkludere egenskaper, eller metoder, for å lagre og manipulere data i objektet. Rene objektorienterte løsninger ble, i motsetning til objektorientert programmering, ingen kommersiell suksess. Tanken er imidlertid delvis videreført som tilleggsfunksjonalitet i SQL-standarden for relasjonsdatabaser.
Utover 2010-tallet kom NoSQL-databaser. Begrepet NoSQL ble første gang brukt i 2009. NoSQL adresserer behovet for å lagre store mengder data med litt struktur, semistrukturelle data, men i en friere form enn det relasjonsdatabaser legger opp til. Populariteten har kommet i kjølvannet av stordata, knyttet til dataanalyse og KI. Teknologisk har utviklingen vært mulig fordi lagringskapasitet er billig og fordi både prosessering og lagring av data kan spres utover flere maskiner i et datanett ved behov.


Kommentarer (2)
skrev Kjell Bratbergsengen
svarte Guro Djupvik
Kommentarer til artikkelen blir synlig for alle. Ikke skriv inn sensitive opplysninger, for eksempel helseopplysninger. Fagansvarlig eller redaktør svarer når de kan. Det kan ta tid før du får svar.
Du må være logget inn for å kommentere.