
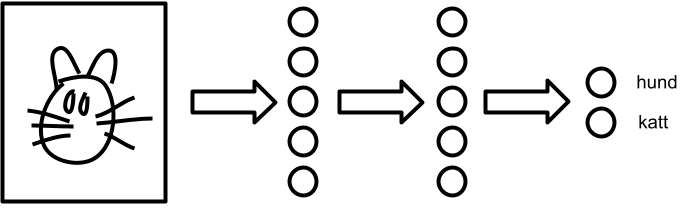
Nevrale nettverk er en teknikk som brukes som byggesteiner innen maskinlæring og kunstig intelligens. De kan ses på som en veldig grov forenkling av hvordan nervecellene i hjernen fungerer. De underliggende prinsippene er svært enkle: nevrale nettverk er bygd opp av «nevroner» (prosesseringsenheter) og koblinger mellom disse nevronene.
Faktaboks
- Uttale
- nevrˈalt nettverk
- Også kjent som
-
kunstig nevralt nettverk

Kommentarer
Kommentarer til artikkelen blir synlig for alle. Ikke skriv inn sensitive opplysninger, for eksempel helseopplysninger. Fagansvarlig eller redaktør svarer når de kan. Det kan ta tid før du får svar.
Du må være logget inn for å kommentere.