
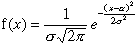
Feillære er en del av matematikken som behandler egenskaper ved tilfeldige feil, og som har som hovedoppgave å beregne tilnærmet riktige verdierut fra et målemateriale med tilfeldige feil.
Faktaboks
- Også kjent som
-
feilteori
Ettersom målinger ikke er fullkomne, foretar man i alminnelighet en rekke målinger for å oppnå større nøyaktighet. Disse målingene er beheftet med feil. Feilene kan først og fremst være systematiske og skyldes uriktige målemetoder, feil i måleinstrumentene, forhold ved målingen og egenskaper ved observatøren som gir uriktige avlesninger og så videre. Men selv om man tar hensyn til systematiske feil, så varierer måleresultatene på grunn av tilfeldige årsaker som man ikke kan kontrollere, og som gir feil som varierer fra én måling til den neste. De feilene som oppstår på denne måten, kalles tilfeldige.
Hvis n målinger av den samme størrelse har gitt en rekke verdier x1,x2,...,xn, antar man som den beste tilnærmelsen for størrelsen et eller annet gjennomsnitt av disse verdiene. Oftest brukes det aritmetiske gjennomsnitt \[a = \frac{1}{n}(x_1 + x_2 + \dotsc + x_n)\] For å angi hvor stor variasjon det er i de funne målingene, innfører man spredningsmål. Et slikt mål er for eksempel middelavviket (den gjennomsnittlige feil) \[m = \frac{1}{n}(|x_1 – a| + \dotso + |x_n – a|)\] som er gjennomsnittet av de enkelte avvik fra a tatt med positivt fortegn. Viktigere er kvadratavviket, s, (standardavviket, engelske standard deviation), definert ved \[s^2 = \frac{1}{n}((x_1 – a)^2 + \dotso + (x_n – a)^2)\] Det aritmetiske gjennomsnittet er den verdien som gjør kvadratavviket minst mulig.

Kommentarer
Kommentarer til artikkelen blir synlig for alle. Ikke skriv inn sensitive opplysninger, for eksempel helseopplysninger. Fagansvarlig eller redaktør svarer når de kan. Det kan ta tid før du får svar.
Du må være logget inn for å kommentere.