
Cache i maskinvaren er et hurtig, privat og midlertidig lager for instruksjoner og data for én prosessor eller en gruppe prosessorer. Hensikten er raskere tilgang til data og instruksjoner. Cache ligger fysisk nær prosessoren, i moderne maskiner på samme brikke. En datamaskin kan ha cache i flere nivåer.
cache
Hensikt
Programmer som er under utførelse ligger i arbeidslageret – det gjelder både instruksjoner og data. Etter hvert som instruksjoner skal utføres og data skal brukes må disse overføres til utførende prosessor over datamaskinenes interne buss. Arbeidslageret er normalt langsomt i forhold til prosessor, og med mange prosessorer i samme system som alle henter instruksjoner og data fra samme lager, blir buss og arbeidslager en flaskehals. Cache avlaster disse og reduserer prosessorers venting på data.
Annen bruk av begrepet cache
Selv om cache tidligere var ensbetydende med midlertidig lagring på lavt nivå, slik som i en prosessor, er i dag begrepet mye benyttet også om andre former for midlertidig lagring.
For eksempel vil de fleste nettlesere ha et cache der innholdet og ressurser for nylig besøkte nettsider ligger lagret. Dersom nettsiden besøkes igjen i løpet av kort tid, vil informasjonen hentes fra nettleserens cache fremfor fra webserveren (så sant ikke innholdet er endret). Dette vil kunne gjøre at nettsidene vises vesentlig raskere, og reduserer bruken av båndbredde og ressurser på webserver.
Effekten av cache
Den positive effekten av cache er basert på antakelsen om at data og instruksjoner brukes konsentrert i tid og rom. Sannsynligheten for at data som nettopp er lastet inn i en cachelinje skal brukes igjen i løpet av kort tid er mye større enn for data som bare ligger i arbeidslager. Dess større cache er dess mindre er sannsynligheten for at en cachelinje blir overskrevet.
Virkemåte
Lesing i arbeidslager blir gjort både for å hente inn neste instruksjon og når en instruksjon leser en operand (et dataord) i arbeidslager. Dataordet har en adresse. Hvis dataordet finnes i cache leses det derfra, hvis ikke hentes det i arbeidslager. Testen på om ordet finnes i cache og forberedelsen til lesing i arbeidslager foregår parallelt, slik at en ikke mister tid.
Når ordet ikke finnes i cache blir en ny cachelinje som inneholder det adresserte ordet lastet inn. En cachelinje inneholder et antall ord etter hverandre, for eksempel 4 eller 8. Den gamle cachelinjen blir overskrevet. Dette åpner også for mer effektiv bruk av buss og arbeidslager, per ord er det mer effektivt å overføre etterfølgende ord enn vilkårlig adresserte enkeltord. Cachelinjen må ha et dataord som inneholder arbeidslageradressen til første ord i den aktuelle cachelinjen.
Cachelageret er mye mindre enn arbeidslageret, og det er bare de sist brukte dataordene som får plass i cache. Testen på om et ord finnes i cache må ta liten tid. En enkel metode er å dividere arbeidslageradressen med cachelagerets størrelse, og bruke divisjonsresten som adresse i cachelageret. Når cachelagerstørrelsen er en potens av 2 – 2k, betyr det at cachelageradressen utgjøres av de siste k bit i arbeidslageradressen. En cachelinje består av 2m byte, den aktuelle cachelinjeadresse blir da de siste k bit i arbeidslageradressen, derav strykes de siste m bit.
Eksempel
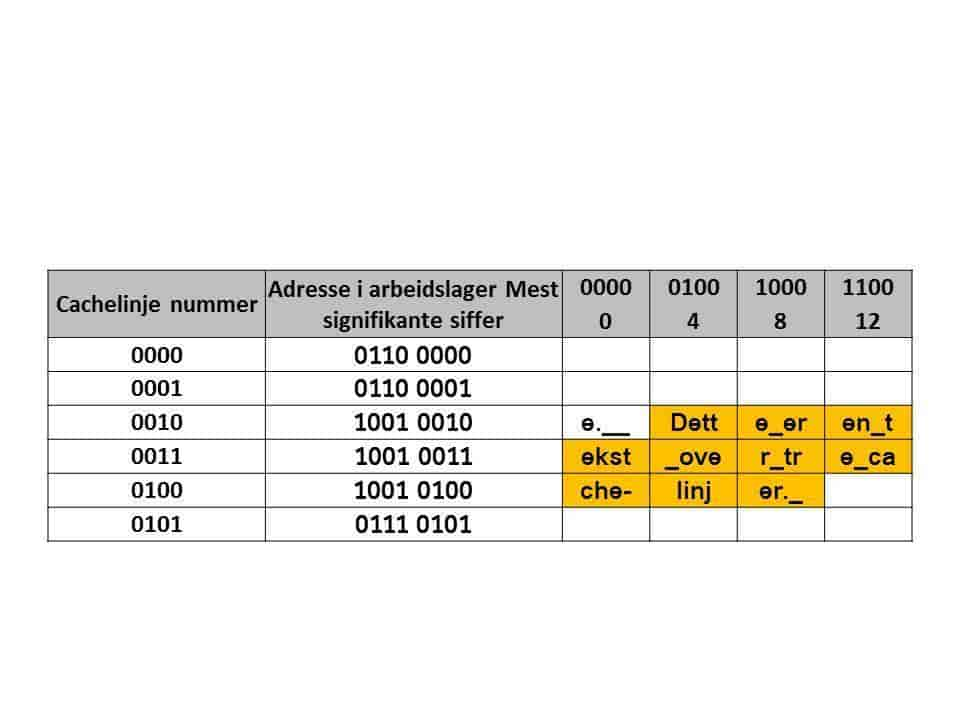
Cache med 16 byte i hver cachelinje. Figuren viser innholdet i cache rett etter at teksten «Dette er en tekst over tre cachelinjer» er lest fra arbeidslageret. I arbeidslageret starter teksten på adresse 1001 0011 0100 med bokstaven «D».
Eksempel som vist i figuren: Cachelageret består av 24=16 cachelinjer. Hver cachelinje har plass til 4 ord, hvert ord er 4 byte, til sammen 16 byte. Byteadressen til hvert ord er vist i kolonnen for hver av de 4 dataordene. Binærsifre vises øverst og desimale siffer er skrevet i linje 2. Dataordet på arbeidslageradresse 1001 0010 0100 som inneholder «Dett» blir plassert på cachelinje 0010, i ordet som har byteadressen 0100 (4). Dataordet beholder sin plass i cache inntil det blir lest fra arbeidslageradresse xxxx 0010 yyyy og xxxx ikke er 1001.
Virkelige cachelager er vesentlig større enn 16 cahelinjer. Fra 210=1024 og oppover er mer vanlig.
Skriving til cache
Skriving kompliseres når det finnes flere prosessorer i systemet med egen cache. Når samme ord i arbeidslager har en kopi i to eller flere cachelager, og en kopi skrives vil samme ord ha to forskjellige verdier. Det kan gi logiske feil og må unngås. Derfor går skriving direkte til arbeidslager, egen cache skrives også, men i andre cachelager må linjen med denne adressen invalideres, det vil si at den ikke kan brukes mer før den er lest på ny.
Cache i flere nivåer
Moderne prosessorbrikker har mange CPUer eller kjerner. En typisk mikromaskin kan ha tre cachenivåer på samme brikke. Hver kjerne har en egen liten cache. To eller en mindre gruppe kjerner har en litt større cache. På nivå tre er det en felles cache for alle kjerner på brikken. Hvis datamaskinene har mange prosessorbrikker er det aktuelt med en felles cache for alle brikkene. Dess høyere nivå og dess lengre fra kjernen, dess større er cache. De samme gjelder hastigheten, det er raskere å hente data i nivå 1 cache enn i nivå 2 cache.
Skille mellom data og instruksjoner
Data og instruksjoner kan ha ulike bruksmønster. Instruksjoner utføres stykkevis fortløpende, gjerne i et repeterende mønster. Data kan ha et mer vilkårlig mønster. Derfor har noen systemer to cachelager, ett for instruksjoner og ett for data.
Cache-bevisste algoritmer
Tidsforskjellen på lesing av data i cache og arbeidslager har etter hvert utviklet seg til å bli stor, særlig når prosessoren har cache på egen brikke. Det har ført til utviklingen av «cache conscious algorithms», cache-bevisste algoritmer. Dess oftere et dataord er brukt, dess større er sannsynligheten for at det ligger i cache. Hvis bare en liten del av en datastruktur blir brukt, for eksempel nøkkelen i en post under sortering, vil det kunne lønne seg å kopiere nøkkelen eller første del av den – til en ny post sammen med en referanse til originalposten. Det forhindrer at cache blir fylt data som ikke blir brukt i sorteringen. De fleste sammenligner mellom nøkler som bestemmer sorteringsrekkefølgen kan avgjøres ved å se på første del av nøkkelen i de to postene som sammenlignes.
Generelle strategier er å konsentrere mye brukte data på minimal plass, og å bruke en gruppe data i en konsentrert periode, og gjerne kombinere begge strategiene.
Forskjellen på cache og buffer
En buffer er en midlertidig lagring mens data venter på å overføres fra et delsystem til et annet. Cache vil derimot være midlertidig lagring før videre behandling i samme system.

Kommentarer
Kommentarer til artikkelen blir synlig for alle. Ikke skriv inn sensitive opplysninger, for eksempel helseopplysninger. Fagansvarlig eller redaktør svarer når de kan. Det kan ta tid før du får svar.
Du må være logget inn for å kommentere.